
2025 AI 研究精選:深度剖析 LLM 預訓練與 Doubao-1.5-pro 模型突破
引言:AI 研究的快速演進與本週焦點
2025 年,人工智慧(AI)技術正以前所未有的速度推進,尤其是在大型語言模型(Large Language Models, LLM)與生成式 AI 領域的突破,正逐步改寫科技與產業的未來。隨著計算能力的提升與數據資源的豐富,AI 不僅在自然語言處理(NLP)上展現驚人表現,更在程式碼生成、安全性、協作系統與倫理訓練等多元面向持續深化。這場 AI 革命不僅是技術的演進,更是人類智慧與機器智能融合的里程碑。
本週(2025 年 12 月 1 日至 7 日),由 DAIR.AI 精選的頂尖 AI 論文涵蓋了多個前沿主題,從強化深度搜尋能力的 DeepSeek-V3.2,到探討程式碼生成安全性的「Is Vibe Coding Safe?」,再到多代理系統的演化協調策略與誠實訓練大型語言模型的新方法,這些研究不僅展現技術創新,也反映了 AI 在安全性、協作與倫理面向的持續關注。這些多元議題的交織,正是當前 AI 研究的縮影,揭示了未來 AI 發展的多重挑戰與機遇。
此外,2025 年的 AI 競爭焦點依然聚焦於 LLM 的預訓練技術,這是驅動模型能力提升的基石。以 ByteDance 最新發布的 Doubao-1.5-pro 為例,其採用多專家模型(Mixture of Experts, MoE)架構,實現了低啟動參數下的高效能,展現了新一代 AI 模型設計的突破。本文將帶您深入解析本週的研究亮點,並結合最新的 LLM 預訓練技術與 Doubao-1.5-pro 模型,全面掌握 2025 年 AI 領域的前沿趨勢與未來展望。
在這個快速變動的時代,理解 AI 研究的最新動態與技術細節,對企業決策者、技術開發者與學術研究者而言,都是不可或缺的競爭優勢。讓我們從本週的頂尖論文出發,揭開 AI 技術演進的神秘面紗,洞察未來智能世界的發展脈絡。

Source: DAIR.AI on X: “Top AI Papers of the Week (Dec 1 – 7):” from DAIR.AI
參考連結:DAIR.AI on X: “Top AI Papers of the Week (Dec 1 – 7):”
本週頂尖 AI 論文概覽與重點解析
2025 年第 48 週,AI 研究領域持續展現多元且深刻的技術突破,DAIR.AI 精選的本週頂尖論文涵蓋了從生成式 AI 模型的深度搜尋能力,到程式碼安全性、多代理系統協調,以及大型語言模型誠實度訓練等多個關鍵議題。這些研究不僅反映了技術創新的前沿,也揭示了 AI 在安全性、協作與倫理層面的持續關注,為業界與學術界提供了寶貴的參考與啟示。
首先,DeepSeek-V3.2 作為一款強化深度搜尋能力的生成式 AI 模型,展現了在資訊檢索與語言生成結合上的新高度。該模型透過改進的架構設計與訓練策略,能夠更精準地理解複雜查詢意圖,並生成更具相關性的回應,對於提升搜尋引擎與智能助理的效能具有重要意義。此研究不僅強調模型在語言理解上的深度,也突顯了生成式 AI 在實際應用中對搜尋效率與準確度的提升潛力。
接著,「Is Vibe Coding Safe?」論文深入探討了程式碼生成技術與安全性的關聯。隨著 AI 在自動程式碼撰寫領域的廣泛應用,如何確保生成程式碼的安全性成為關鍵挑戰。該研究分析了生成程式碼中潛在的安全漏洞與風險,並提出了相應的檢測與防範機制,為未來 AI 輔助開發工具的安全設計提供了理論基礎與實務指引。此議題對於企業在導入 AI 程式碼生成技術時,保障系統安全與資料隱私尤為重要。
此外,「Quiet Feature Learning」提出了一種靜態特徵學習的新方法,強調在無監督或弱監督環境下,如何有效提取穩定且具代表性的特徵。這對於提升模型在多樣化任務中的泛化能力與魯棒性具有深遠影響。該方法透過降低特徵噪音與冗餘,促進模型更精準地捕捉資料內在結構,進一步推動 AI 在視覺、語音及文本等多模態領域的應用。
在雲端系統領域,「Autonomous Cloud Reliability」探討了自動化雲端系統的可靠性問題。隨著 AI 服務大量部署於雲端平台,系統的穩定性與容錯能力成為關鍵指標。該研究提出了基於 AI 的自動監控與修復機制,能夠即時偵測異常並自動調整資源配置,提升整體系統的可用性與效能。這對於保障企業級 AI 應用的連續運行與服務品質至關重要。
「Thinking with Programming Vision」則結合程式設計與視覺推理,開創了跨領域的智能思考模式。該研究展示了如何利用程式語言結構輔助視覺任務的推理過程,提升模型在複雜場景下的理解與決策能力。這種融合策略不僅擴展了 AI 的認知範疇,也為未來智能系統的多模態交互奠定基礎。
多代理系統的協調問題在「Evolving Multi-Agent Orchestration」中獲得深入探討。該論文提出了演化式協調策略,促使多個智能代理在動態環境中達成高效合作。透過自適應學習與策略演化,系統能夠在複雜任務中實現資源最佳分配與任務協同,對於智慧城市、機器人群體控制等應用場景具有重要價值。
最後,「Training LLMs for Honesty via Confessions」提出了一種創新的訓練方法,透過「懺悔」機制提升大型語言模型的誠實度。此方法鼓勵模型在面對不確定或敏感問題時,能夠坦誠表達不確定性或拒絕回答,減少錯誤資訊的生成。這對於增強 AI 的倫理性與可信度,尤其在醫療、法律等高風險領域應用中,具有深遠的意義。
| 論文名稱 | 研究重點 | 技術特色 | 應用前景 |
|---|---|---|---|
| DeepSeek-V3.2 | 強化深度搜尋能力 | 生成式 AI 模型,提升查詢理解與回應準確度 | 搜尋引擎、智能助理 |
| Is Vibe Coding Safe? | 程式碼生成安全性 | 安全漏洞檢測與防範機制 | AI 程式碼生成工具 |
| Quiet Feature Learning | 靜態特徵學習 | 降低特徵噪音,提升泛化能力 | 多模態學習、無監督學習 |
| Autonomous Cloud Reliability | 自動化雲端系統可靠性 | AI 驅動的監控與自動修復 | 雲端服務穩定性 |
| Thinking with Programming Vision | 程式設計與視覺推理結合 | 跨領域智能推理 | 多模態交互、智能決策 |
| Evolving Multi-Agent Orchestration | 多代理系統協調 | 演化式協調策略 | 智慧城市、機器人群體控制 |
| Training LLMs for Honesty via Confessions | 提升 LLM 誠實度 | 懺悔訓練機制 | AI 倫理、醫療與法律應用 |
這些論文的多元主題與技術深度,充分展現了 2025 年 AI 研究的廣度與深度。從模型架構的創新,到安全性與倫理的嚴謹考量,再到系統協作與智能推理的突破,均反映出 AI 領域正朝向更高效、更安全且更可信的方向發展。這些研究成果不僅為學術界提供了豐富的理論基礎,也為產業界帶來實際的技術指引,推動 AI 技術在各行各業的落地與應用。
Source: AK on X: “ByteDance announces Doubao-1.5-pro” from _akhaliq
綜合本週論文精選,我們可以看到 AI 技術的演進不僅依賴於模型本身的性能提升,更重視安全性、協作性與倫理性的平衡。這些研究成果將成為未來 AI 發展的重要基石,為打造更智慧、更可靠的人工智慧系統提供堅實支撐。
參考連結:DAIR.AI on X: “Top AI Papers of the Week (Dec 1 – 7):”
深入解析 LLM 預訓練:AI 能力的基石
在 2025 年,隨著大型語言模型(LLM)成為人工智慧領域的核心技術,預訓練階段的重要性愈發凸顯。LLM 預訓練不僅是模型學習語言結構與知識的基礎,更是決定模型性能與應用潛力的關鍵環節。本文將從三大核心步驟–網路數據處理、斷詞與編碼、神經網路訓練,深入剖析 LLM 預訓練的技術細節與實務意義,幫助讀者全面理解這一 AI 能力的基石。
本文大綱
網路數據處理:打造高品質預訓練資料庫
LLM 的表現高度依賴於預訓練數據的質量與規模。2025 年,HuggingFace 推出的 FineWeb 數據集成為業界標竿,該數據集包含高達 15 兆個 token,佔用 44TB 磁碟空間,主要來源於 CommonCrawl 網頁快照。FineWeb 之所以卓越,在於其嚴謹且透明的數據過濾流程,涵蓋多層面篩選:
- URL 過濾:根據預設黑名單阻擋成人內容、垃圾郵件及其他不良網站,確保初步數據安全與合規。
- 文字抽取:剔除 HTML、JavaScript 等非文本元素,保留純淨且有意義的語言內容。
- 語言篩選:利用 fastText 分類器,僅保留英語文本,且信心分數需達 0.65 以上,提升語言一致性。
- 低質量文本過濾(Gopher Filtering):剔除重複、無意義或有害內容,確保數據多樣且高質。
- 重複內容去除(MinHash Deduplication):透過 MinHash 技術高效辨識並刪除近似重複文本,避免模型過度擬合。
- C4 過濾器與客製化規則:進一步清理模板化內容與格式異常,提升數據整體品質。
- 個人識別資訊(PII)移除:嚴格刪除姓名、地址、電話等敏感資訊,保障隱私安全。
這套多層次的數據處理管線,最終將原始數據縮減至約 36 兆 tokens,為神經網路訓練提供了乾淨且多元的語料基礎。FineWeb 的成功示範了高品質數據對 LLM 預訓練成效的決定性影響,成為 2025 年 AI 領域不可或缺的資源。

Source: HuggingFaceFW/fineweb
斷詞與編碼:將文字轉化為模型可理解的語言單位
完成數據清洗後,下一步是將龐大的文字資料轉換成神經網路能處理的「token」序列。斷詞(Tokenization)是此階段的核心技術,目標是將原始文本拆解成更小的語言單位,這些單位既能保留語義,又能有效縮短序列長度。
傳統的文字編碼以字元為單位,使用 UTF-8 編碼將每個字元轉成 8 位元(1 byte),共 256 種可能符號。然而,單純以字元為單位會導致序列過長,訓練效率低下。為此,現代 LLM 採用 Byte Pair Encoding(BPE) 技術,透過反覆合併高頻字元組合,形成更大粒度的 token。例如,常見詞彙或字串會被合併成單一 token,減少序列長度同時擴充詞彙表。
以 GPT-4 為例,其詞彙表大小約為 100,277 個 token,這個規模在平衡序列長度與詞彙豐富度間取得最佳折衷。斷詞過程中,空格、標點符號、常用詞組等都會被拆分或合併成不同 token,這使得模型能更靈活地捕捉語言結構與語義。
舉例來說,短語「hello world」會被斷詞成兩個 token:「hello」與「space + world」,而空格的有無會影響 token 的劃分,反映出模型對細微語言差異的敏感度。這種精細的斷詞策略不僅提升了訓練效率,也為後續的語言理解與生成奠定了堅實基礎。

Source: Tiktokenizer
神經網路訓練:從數據到智慧的數學演算
斷詞完成後,token 序列即成為神經網路的輸入。神經網路模擬人腦神經元的運作,透過多層節點(neurons)與連結權重(weights)進行複雜的數學計算,學習 token 之間的統計關係與語言規律。現代 LLM 幾乎皆基於 Transformer 架構,該架構引入自注意力機制(Self-Attention),能有效捕捉長距離語言依賴,提升語境理解能力。
訓練過程中,模型會根據輸入 token 預測下一個 token,並計算預測結果與真實標籤間的損失函數(如交叉熵損失)。透過反向傳播(Backpropagation)與梯度下降(Gradient Descent)演算法,模型不斷調整權重,逐步提升預測準確度。這種迭代優化過程類似於調音樂器,讓模型在大量語料中學習語言的統計模式。
以下為神經網路訓練的關鍵步驟:
| 步驟 | 說明 |
|---|---|
| 輸入表示(Input Representation) | 將 token 序列轉換為數值向量,作為神經網路的輸入。 |
| 數學運算(Mathematical Processing) | 利用權重矩陣進行加權和、正規化、激活函數等運算,提取語言特徵。 |
| 預測輸出(Prediction Output) | 產生下一個 token 的機率分布,選擇最可能的 token 作為預測結果。 |
| 損失計算(Loss Calculation) | 計算預測結果與真實標籤間的誤差,作為優化目標。 |
| 反向傳播(Backpropagation) | 根據損失函數計算梯度,調整權重以減少誤差。 |
| 參數更新(Parameter Update) | 使用優化器(如 Adam)更新模型參數,提升模型性能。 |
透過數十億甚至數千億的參數,LLM 能夠捕捉語言的複雜結構與語義關係,實現流暢且具邏輯性的文本生成。儘管神經網路的運作本質是數學函數,但其強大的模式識別能力使得 LLM 在多種自然語言處理任務中表現卓越。

Source: Andrej Karapathy
小結
LLM 預訓練是現代 AI 技術的基石,涵蓋從龐大且高品質的網路數據處理,到精細的斷詞編碼,再到複雜的神經網路訓練。每一環節都直接影響模型的語言理解與生成能力。FineWeb 等數據集的出現,為預訓練提供了堅實的數據保障;而先進的斷詞技術與 Transformer 架構,則確保了模型能高效且精準地學習語言規律。隨著技術不斷演進,預訓練方法的優化將持續推動 AI 模型性能的提升,為 2025 年及未來的人工智慧發展奠定堅實基礎。
參考連結:A Comprehensive Guide to Pre-training LLMs
ByteDance Doubao-1.5-pro:高效 MoE 架構的突破
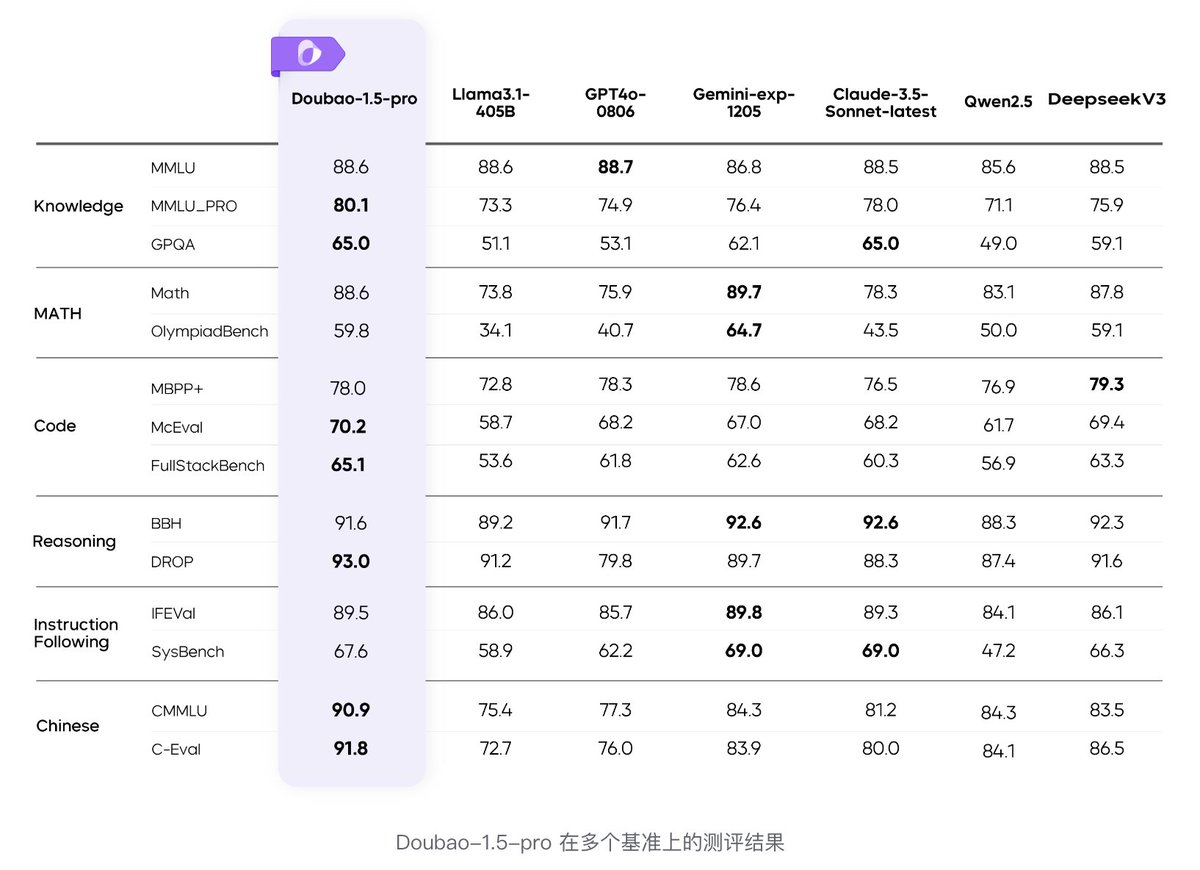
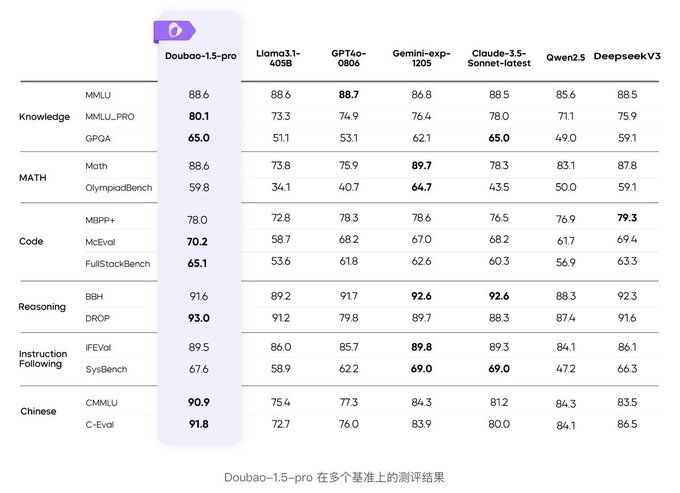
2025 年初,ByteDance 正式發布了其最新大型語言模型 Doubao-1.5-pro,這款模型以其創新的多專家模型(Mixture of Experts, MoE)架構,成為當前 AI 領域的焦點。MoE 架構的核心優勢在於「激活參數」的選擇性啟用,讓模型在保持高性能的同時,大幅降低計算資源的消耗,實現了性能與效率的雙重突破。Doubao-1.5-pro 採用約 200 億的啟動參數,卻能達到相當於 1400 億參數的密集模型性能,這種約 7 倍的性能槓桿效應,為大型語言模型的設計與部署帶來了全新思路。
Doubao-1.5-pro 在多項主流基準測試中表現優異,超越了 DeepSeek-V3、GPT4o 以及 Llama3.1-405B 等傳統 Transformer 模型。尤其在 AIME 基準測試中,其「Deep Thinking」模式更是超越了 ByteDance 自家先前的 O1-preview 與 O1 模型,展現出強大的推理與理解能力。這不僅反映了 MoE 架構在提升模型深度思考能力上的潛力,也顯示出 ByteDance 在 AI 研發上的技術積累與創新實力。
| 模型名稱 | 參數規模 | 架構類型 | 性能亮點 | 啟動參數比例 |
|---|---|---|---|---|
| DeepSeek-V3.2 | 未公開 | 傳統 Transformer | 強化深度搜尋能力 | 全參數啟動 |
| GPT4o | 未公開 | 傳統 Transformer | 高推理能力 | 全參數啟動 |
| Llama3.1-405B | 4050 億 | 傳統 Transformer | 大規模參數,強大語言理解能力 | 全參數啟動 |
| Doubao-1.5-pro | 約 200 億啟動參數 | MoE | 7 倍性能槓桿,低延遲高吞吐量 | 1/7 啟動參數(相當於 1400 億) |
MoE 架構的設計理念是將模型分成多個「專家」子網絡,根據輸入動態選擇部分專家進行計算,避免了傳統 Transformer 模型中所有參數都必須同時激活的高昂成本。這種「稀疏激活」策略不僅降低了推理延遲,也使得模型在硬體資源有限的情況下,依然能保持強大的語言理解與生成能力。Doubao-1.5-pro 進一步在工程層面採用了異構系統設計,優化了預填充(prefill)與解碼(decode)流程,兼顧高吞吐量與低延遲需求,滿足實際應用中對即時反應的嚴苛要求。
此外,Doubao-1.5-pro 的「Deep Thinking」模式,透過更深層次的推理與上下文理解,提升了模型在複雜任務中的表現。這種模式不僅在標準測試中取得領先成績,也為未來 AI 在專業領域的應用奠定基礎,例如法律諮詢、醫療診斷與技術研發等需要高精度推理的場景。ByteDance 透過 Doubao-1.5-pro 展示了 MoE 架構在大型語言模型中的巨大潛力,為 AI 模型的高效能與可擴展性提供了新範式。
Source: AK on X: “ByteDance announces Doubao-1.5-pro” from _akhaliq
綜觀 2025 年 AI 模型發展趨勢,Doubao-1.5-pro 的成功標誌著 MoE 架構已從理論走向成熟實踐,成為提升大型語言模型性能與效率的關鍵技術。相較於傳統全參數啟動的 Transformer 模型,MoE 不僅節省了大量計算資源,也降低了運營成本,對企業部署 AI 解決方案具有重要意義。未來,隨著硬體技術與分布式計算的進步,MoE 架構有望在更多領域實現突破,推動 AI 技術向更高層次發展。
對於研究者與開發者而言,深入理解 Doubao-1.5-pro 的架構設計與工程優化策略,將有助於掌握 AI 模型效率提升的核心技術。MoE 架構的靈活性與擴展性,也為定制化 AI 解決方案提供了廣闊空間,能夠根據不同應用需求調整專家數量與激活策略,實現性能與成本的最佳平衡。這種技術路線的成功,無疑將引領未來大型語言模型的設計方向,成為 AI 競爭的新焦點。
參考連結:AK on X: “ByteDance announces Doubao-1.5-pro”
LLM 預訓練與基礎模型的比較與應用
在 2025 年,隨著大型語言模型(LLM)技術的持續演進,預訓練階段依然是 AI 能力提升的核心基石。LLM 預訓練不僅決定了模型的語言理解深度,也影響其後續微調與應用的廣度與精準度。本文將深入探討 LLM 預訓練的本質、基礎模型(Base Model)的特性,並以 OpenAI 2019 年推出的 GPT-2 為例,對比現代大型 LLM 的發展,幫助讀者全面理解預訓練與基礎模型在 AI 生態中的關鍵角色。
LLM 預訓練:從海量數據到語言模式學習
LLM 預訓練階段的核心目標是讓模型學習語言的統計規律與語境關聯,透過海量文本資料的反覆訓練,模型能夠預測下一個 token(語言單位),進而生成連貫且具語義的文本。這一過程類似於「閱讀」大量書籍與網頁,模型並非真正理解語意,而是透過模式識別與概率計算,掌握語言的結構與用法。
以 GPT-2 為例,其基礎模型擁有約 16 億參數,訓練於約 1000 億個 token,最大上下文長度為 1024 token。雖然在當時已具備生成流暢文本的能力,但因為訓練資料與模型規模的限制,GPT-2 在理解用戶意圖與指令遵循方面仍有不足。這也反映出基礎模型的本質:它是一個「網路文件模擬器」,能夠模仿網路文本的語言風格,但尚未具備真正的任務適應性與交互能力。
隨著技術進步,現代大型 LLM 如 Llama 3,參數規模已達 4050 億,訓練資料規模擴展至 15 兆 token,最大上下文長度可達數千 token,這使得模型在語義理解、推理能力與多任務適應性上有了質的飛躍。這種規模的提升不僅增強了模型的生成能力,也為後續的微調與強化學習奠定了堅實基礎。
| 特性 | GPT-2 基礎模型 | 現代大型 LLM(如 Llama 3) |
|---|---|---|
| 參數規模 | 16 億 | 4050 億 |
| 訓練資料規模 | 約 1000 億 token | 15 兆 token |
| 最大上下文長度 | 1024 token | 可達數千 token |
| 任務適應性 | 需微調或提示工程 | 支援更廣泛的下游任務 |
| 理解與生成能力 | 基本文本生成 | 更強語義理解與推理能力 |
這張表格清楚展示了基礎模型與現代大型 LLM 在規模與能力上的差異,反映出預訓練資料量與模型參數規模對 AI 性能的直接影響。
基礎模型的限制與應用場景
基礎模型雖然能生成流暢且語法正確的文本,但其生成內容多為訓練資料的統計重組,缺乏對語境與用戶需求的深度理解。這使得基礎模型在實際應用中,尤其是需要精確回答、指令遵循或專業領域知識的場景,表現有限。
例如,GPT-2 在推理長篇文章或多輪對話時,容易出現上下文遺失或語義偏差,且無法有效識別用戶意圖。這也解釋了為何大多數基礎模型不會直接公開釋出,而是作為後續微調與強化學習的基礎。透過微調,模型能夠針對特定任務或領域進行優化,提升準確度與實用性。
基礎模型的另一個重要價值在於其「可塑性」。研究者與開發者可以基於基礎模型,結合提示工程(Prompt Engineering)、微調(Fine-tuning)及強化學習(Reinforcement Learning),打造符合特定需求的 AI 助手或應用。例如,醫療領域的診斷輔助系統、法律文件分析工具,或是客服聊天機器人,都依賴於基礎模型的靈活調整。
GPT-2 的推理機制與限制
在推理階段,GPT-2 採用「逐 token 生成」的方式,根據前文上下文預測下一個最可能的 token,並將其加入序列中,反覆迭代直到生成完整文本。這種自回歸(autoregressive)生成方式使模型能夠產生連貫的語句,但也限制了其對長距離依賴的捕捉能力。
此外,GPT-2 的最大上下文長度為 1024 token,對於需要長篇連貫推理的任務存在瓶頸。缺乏顯式記憶機制(如後期模型引入的檢索增強生成 Retrieval-Augmented Generation, RAG)也使其無法動態調用外部知識,容易產生偏見或重複訓練資料中的內容。
這些限制促使後續模型在架構設計、上下文長度擴展與知識整合方面持續創新,提升模型的實用性與安全性。
預訓練與基礎模型的戰略意義
LLM 預訓練與基礎模型的發展,不僅是技術層面的突破,更是 AI 產業競爭的核心戰場。企業與研究機構透過擴大訓練資料規模、優化模型架構與提升訓練效率,爭奪 AI 技術領先地位。
以 ByteDance 最新發布的 Doubao-1.5-pro 為例,其採用多專家模型(MoE)架構,在保持高性能的同時,大幅降低啟動參數數量,實現了性能與效率的平衡。這種創新架構的成功,正是基於對基礎模型與預訓練技術深刻理解的結果。
對於開發者而言,掌握基礎模型的特性與預訓練流程,有助於設計更具針對性的微調策略,提升 AI 應用的準確度與用戶體驗。對企業來說,理解這些技術細節則是制定 AI 投資與部署策略的關鍵。

Source: HuggingFaceFW/fineweb from Analytics Vidhya
綜合來看,LLM 預訓練與基礎模型的比較與應用,揭示了 AI 模型從「語言模擬」到「智能助手」的演進路徑。隨著訓練資料規模與模型參數的爆炸性增長,未來的 AI 將更具語義理解力與任務適應性,推動各行各業的智能化轉型。
欲深入了解 LLM 預訓練的技術細節與最新研究,歡迎參考以下連結:
深入閱讀:A Comprehensive Guide to Pre-training LLMs
結論:預訓練是 AI 未來競爭的關鍵戰場
在 2025 年,隨著人工智慧技術的持續突破,大型語言模型(LLM)預訓練的重要性愈發凸顯,成為 AI 領域競爭的核心戰場。預訓練不僅是模型能力的基石,更是決定 AI 系統性能、效率與應用廣度的關鍵因素。從海量數據的嚴格篩選、精細的斷詞編碼,到複雜的神經網路訓練,每一環節都直接影響模型的語言理解深度與推理能力。這種技術積累與創新,正驅動著 AI 向更高階的智能邁進。
首先,預訓練階段的數據質量與規模是決定模型表現的關鍵。FineWeb 等大型數據集以其 15 兆 token 的龐大規模和嚴格的過濾機制,確保了訓練資料的多樣性與純淨度,為模型提供了豐富且可靠的語言樣本。這種高品質數據的支撐,使得現代 LLM 能夠在語義理解、上下文推理及多任務適應性上取得顯著提升。與此同時,斷詞技術如 Byte Pair Encoding(BPE)有效縮短序列長度,提升訓練效率,並平衡詞彙豐富度與計算負擔,為神經網路的高效學習奠定基礎。
其次,神經網路架構的演進,尤其是 Transformer 與多專家模型(MoE)架構的應用,為預訓練帶來了革命性的性能提升。以 ByteDance 的 Doubao-1.5-pro 為例,其採用 MoE 架構,僅啟動約 200 億參數,卻能達到相當於 1400 億參數的性能,實現了 7 倍的性能槓桿,兼顧高吞吐量與低延遲需求。這種架構創新不僅降低了運算成本,也提升了模型的靈活性與擴展性,成為未來 AI 模型設計的重要方向。
| 模型名稱 | 參數規模 | 架構類型 | 性能亮點 | 啟動參數比例 |
|---|---|---|---|---|
| DeepSeek-V3.2 | 未公開 | 傳統 Transformer | 強化深度搜尋能力 | 全參數啟動 |
| GPT4o | 未公開 | 傳統 Transformer | 高推理能力 | 全參數啟動 |
| Llama3.1-405B | 4050 億 | 傳統 Transformer | 大規模參數,強大語言理解能力 | 全參數啟動 |
| Doubao-1.5-pro | 約 200 億啟動參數 | MoE | 7 倍性能槓桿,低延遲高吞吐量 | 1/7 啟動參數(相當於 1400 億) |
這張表格清晰呈現了不同模型在架構與性能上的差異,凸顯了 MoE 架構在提升效率與性能上的巨大潛力。
此外,預訓練的戰略意義不僅限於技術層面,更是企業與研究機構爭奪 AI 領先地位的關鍵。隨著 AI 技術的普及與應用場景的多元化,掌握高效且精準的預訓練技術,成為打造競爭優勢的必備條件。企業若能深入理解預訓練流程,結合基礎模型的特性,制定針對性的微調與強化學習策略,將能快速推出符合市場需求的智能產品,提升用戶體驗與商業價值。
Source: HuggingFaceFW/fineweb from Analytics Vidhya
總結來說,LLM 預訓練是 AI 未來競爭的關鍵戰場,涵蓋了從數據收集、過濾、斷詞,到神經網路訓練與架構創新的全方位技術挑戰。隨著 Doubao-1.5-pro 等新一代模型的問世,預訓練技術正引領 AI 進入一個更高效、更智能的時代。面對這場 AI 革命,無論是企業還是研究者,都必須積極掌握預訓練技術,才能在未來的 AI 競爭中立於不敗之地。
立即關注最新 AI 研究動態,持續提升您的 AI 競爭力,迎接預訓練帶來的無限可能!
參考連結:A Comprehensive Guide to Pre-training LLMs
參考連結:AK on X: “ByteDance announces Doubao-1.5-pro”


你也可能喜歡

生成式 AI 定價與價值傳遞策略:提升市場競爭力的關鍵

AI 圖像生成技術革命:Ideogram2a 的效率與成本突破
