
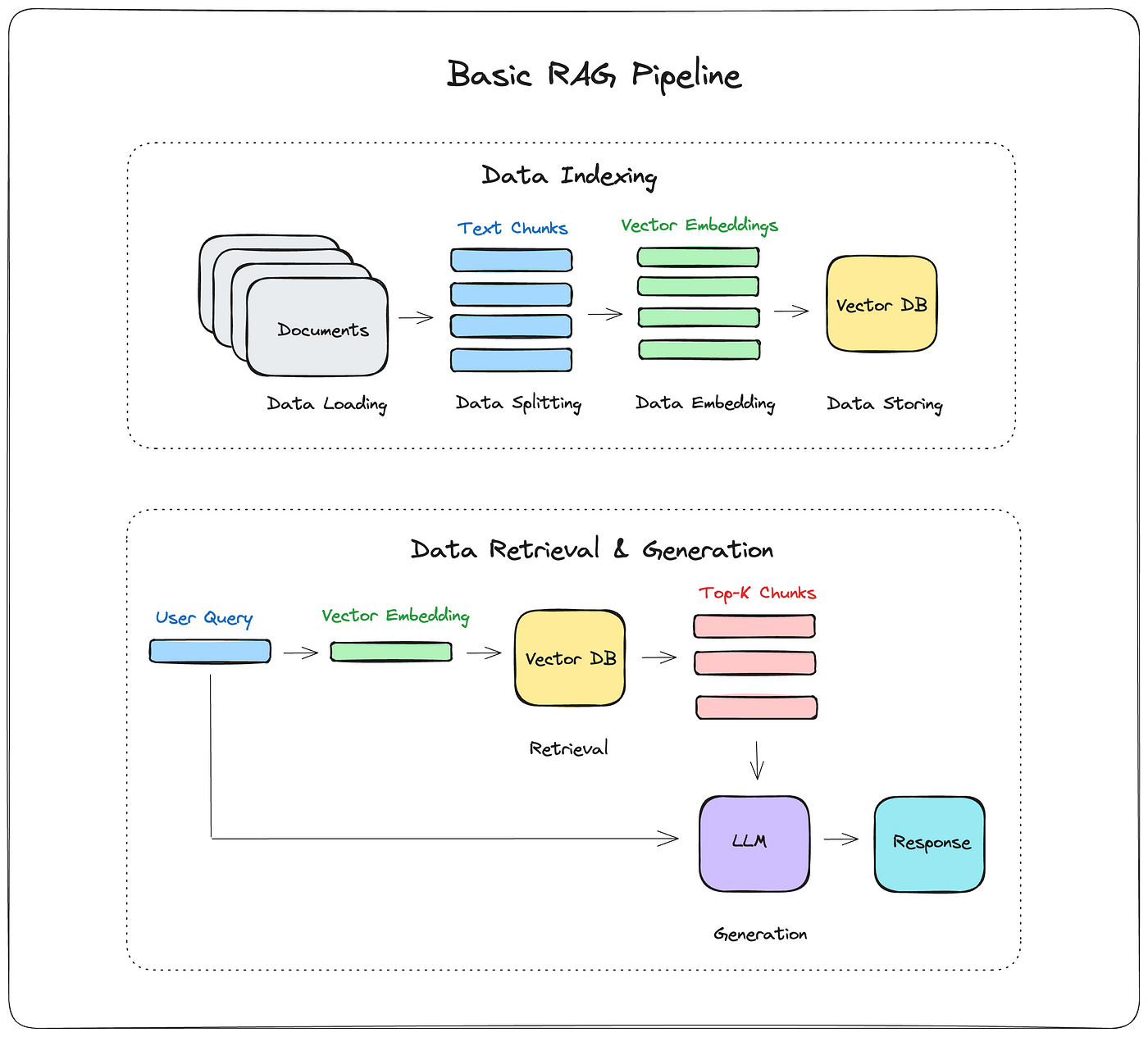
RAG技術終極入門:基礎架構與工作原理詳解
RAG 技術概述 RAG(Retrieval Augment…
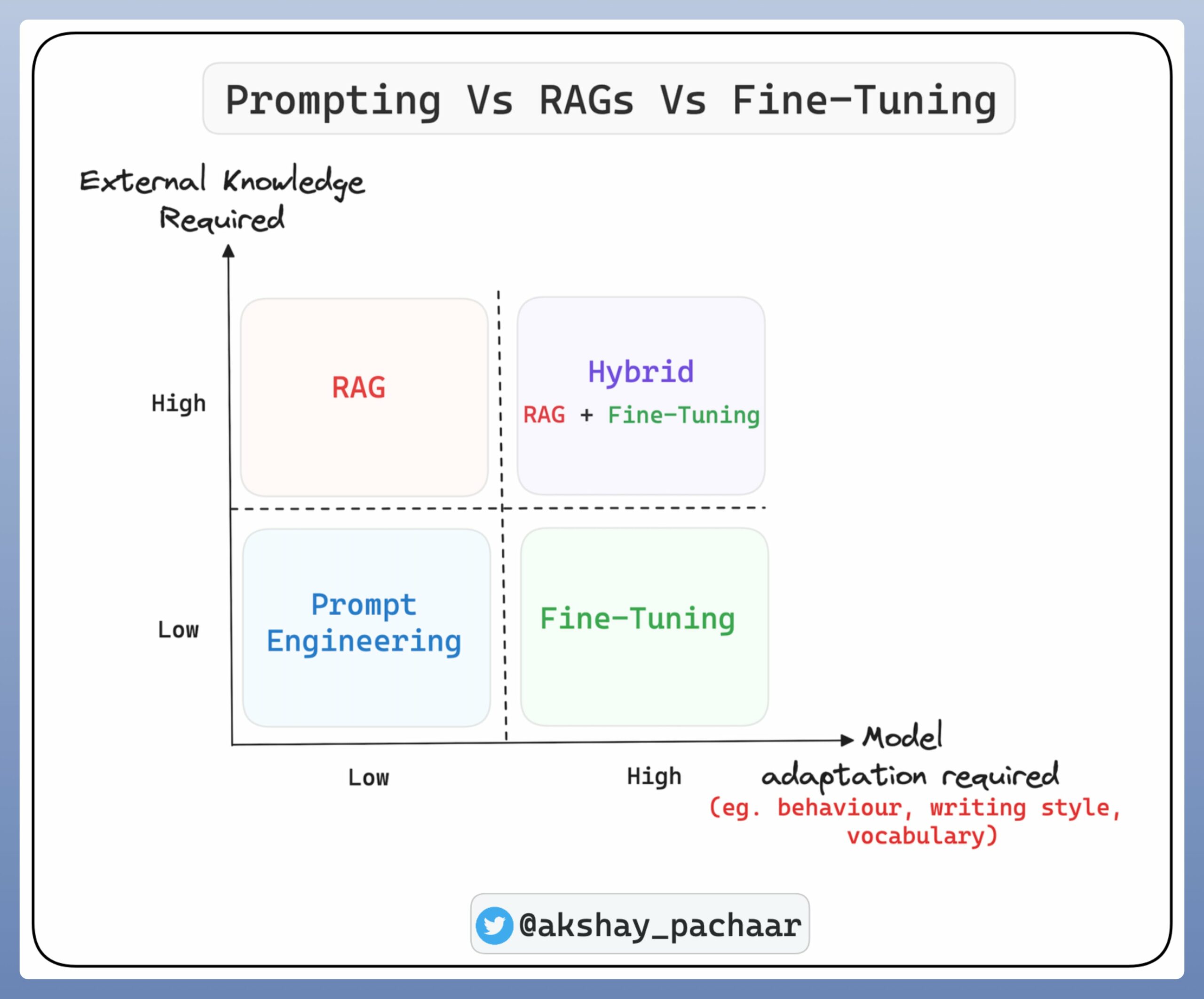
全參數微調、PEFT、提示工程和RAG:哪種 LLM 導入策略最適合我?
隨著 AI 技術的不斷進步,企業正越來越多地尋求將大型語言模…
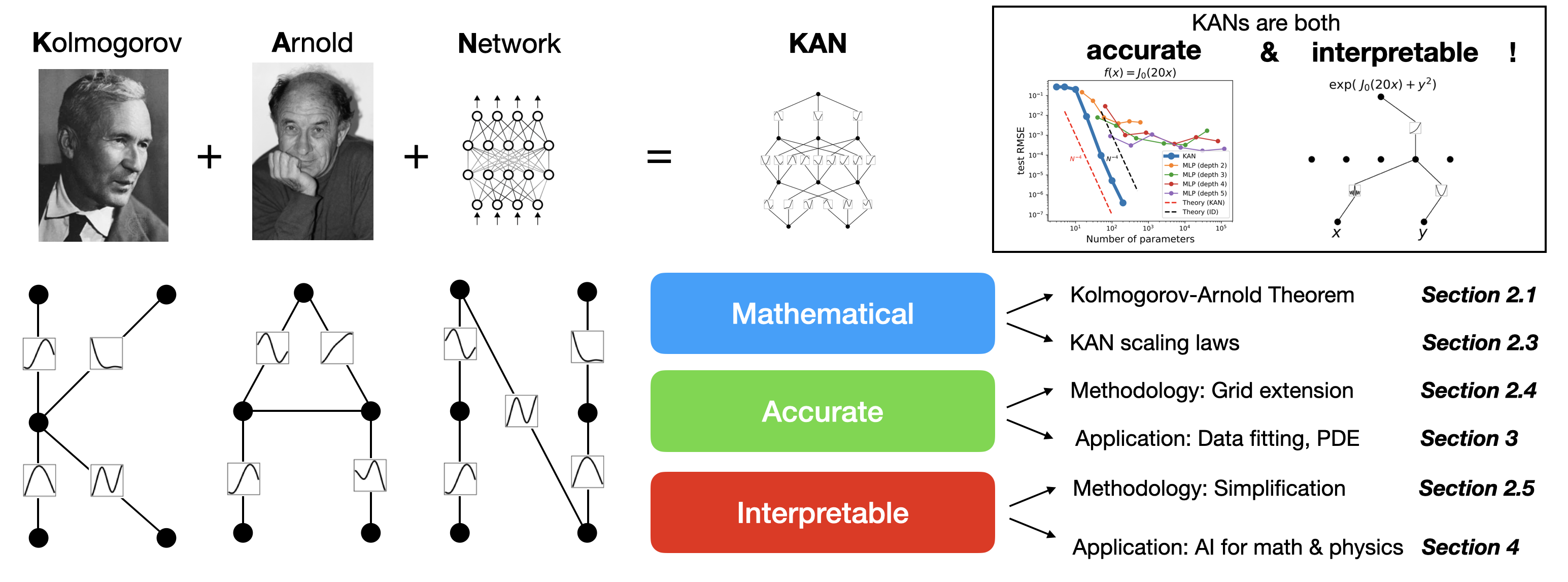
從 Transformer 到 Kansformer? KAN 網絡以結構優化提高模型參數效率與可解釋性
近年來,深度學習技術在多個領域實現了突破性進展,從語言處理到…

 martech_jy
martech_jy- Knowledge Graph , 資料庫
- 27 4 月, 2024
- 927 views
使用 Docker 快速部署最新版 Neo4j 資料庫
在本教學中,我們將學習如何使用 Docker 快速部署 Ne…

- martech_jy
- NLP , 資料科學
- 13 3 月, 2023
- 711 views
【論文筆記】DCFEE:基於自動標記訓練數據的文檔級中文金融事件抽取系統
抽取金融事件能幫助用戶獲得競爭對手的戰略,預測股票市場做出正確的投資決策。舉例來說,股權凍結事件將對公司產生不利影響,股票持有者應迅速判斷避險

- JiunYi Yang
- NLP , 資料產品開發
- 6 3 月, 2023
- 1310 views
使用 OpenAI Finetune API 微調出自己的模型(附程式碼)
今天這篇要教大家如何使用 OpenAI Finetune A…
![[PyTorch] 使用 torch.distributed 在單機多 GPU 上進行分散式訓練](https://www.idataagent.com/wp-content/uploads/2021/02/pexels-photo-270360.jpeg)
- JiunYi Yang
- NLP , Python , PyTorch , 資料科學
- 7 1 月, 2023
- 1406 views
[PyTorch] 使用 torch.distributed 在單機多 GPU 上進行分散式訓練
Finetune 語言模型所需要的 GPU memory 比較多,往往會需要我們能夠利用到多顆 GPU 的資源。今天這篇文章會說明 DataParallel 和 DistributedDataParallel + DistributedSampler 兩種進行模型分散式訓練的方式。
- martech_jy
- NLP , 網路爬蟲 , 資料科學
- 19 12 月, 2022
- 1157 views
經典 NLP 任務標籤生成:串接非官方 ChatGPT API
這篇文章紀錄我串接非官方 ChatGPT API 「試圖」取得 NLP 資訊抽取任務標籤的過程。結論是…

1


2
3

4

5

6
